
Any successful tech company that has been in the market for more than a few years and consists of more than one team on a steadily growing code base is familiar with constantly growing complexity. The build and deployment processes are getting complicated and tedious; the coordination between the teams becomes more and more complex. Often, software development even seems to slow down, even though the company is growing and more developers are joining the teams.
A promising approach to get the complexity under control is to split the code base. Adding interfaces makes the overall system more complex, because more code (and possibly infrastructure) is needed to begin with. So there must be a benefit that justifies this cost. This benefit lies in the fact that the entire system no longer needs to be understood in depth. Developers can ignore - given a good split - large parts of the system and thus also large parts of the complexity during their daily work. Each team can focus on its part of the software. For the other parts, knowing the relevant interfaces is enough.
Splitting software is therefore a conscious “trade-off”: The costs of interfaces are accepted so that the team focus on one part of the software. It goes without saying that the costs should be minimized.
Criteria for finding good boundaries
There are many possible ways in which an existing system can be split. To evaluate the variants in a meaningful way, it is not enough to consider only technical aspects. In the end, the entire organization must be able to cope with the new split. For an easier evaluation, the following three organizational criteria have proven useful:
-
Autonomy: Autonomy is the key factor that allows a team to move quickly without being constantly interrupted by requests from other teams and without being stuck waiting for other teams.
-
Purpose: No team should work on a hodgepodge of unrelated individual topics. Ideally, each team has a clear purpose, which can be formulated in one sentence. The team acts on its own responsibility, always has a clear focus and independently pursues actions that drive their purpose.
-
Balance: No team should be the bottleneck for every important feature, and no team should work on only unimportant peripheral topics. A balanced distribution is possible.
Let’s apply these criteria to two well-known architecture patterns:
Layer Architecture
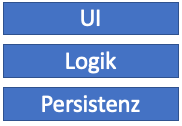
The classic division into 3 layers is a good idea when it comes to structuring code on a small scale. Nevertheless, the pattern is obviously not useful on a cross-team, organizational level: the layered architecture does not allow teams to work autonomously. A “UI team” could not implement anything without constantly coordinating with the “business logic team” or the “persistence team”. In addition, each team would have to work on tasks from all areas of business and would have no clear purpose.
Data-driven Architecture
A data-driven split is another frequently chosen approach. Imagine an e-commerce platform for wines. There could be one service that knows everything about the wine. Other components would provide data for the vineyard, the buyer, or orders.

For search, the wine service only needs to know the basic data: price, name, type, item number and vintage. In the product view, the wine connoisseur wants to know the ideal temperature, residual sugar, acid and alcohol content. During the ordering process, other data is relevant again: availability, quantity discount, shipping costs and delivery estimates. In practice, hundreds of values quickly come together for seemingly simple entities. A team that manages such a service has to deal with many use cases throughout the entire business process spanning from the initial marketing to the final invoice. Focus on one part of the process or one topic is almost impossible. Such a team would also be considered not truly autonomous, as the collaboration of almost all departments would be necessary.
Splitting software with Domain Driven Design
Domain Driven Design is one of the topics that almost everyone in the IT environment has encountered in recent years. Despite its rich toolbox, only a single concept is needed to split a software system: The Bounded Context. A Bounded Context is a delimited area in which each technical term has exactly one meaning.
Many terms have a contextual meaning in everyday life, which most people intuitively understand correctly without being aware of it. For example, the term newspaper can mean the individual printed edition as well as the company publishing said newspaper. The term school can mean the institution (Lisa goes to school) or the building (the school will be renovated next year). Many software models are unnecessarily complex because different meanings of technical terms are not recognized and are combined into the same data model.
Often, a structured approach is necessary to find useful boundaries because the difference in meaning of the terms used withing a company are often more subtle than in everyday life. An ideal method to capture the “big picture” of a system and to work out the contexts based on events is Event Storming. In the following blog post on this topic, we will use this method to dissect the fictitious wine portal in a step-by-step, easy-to-follow manner.
